Abstract
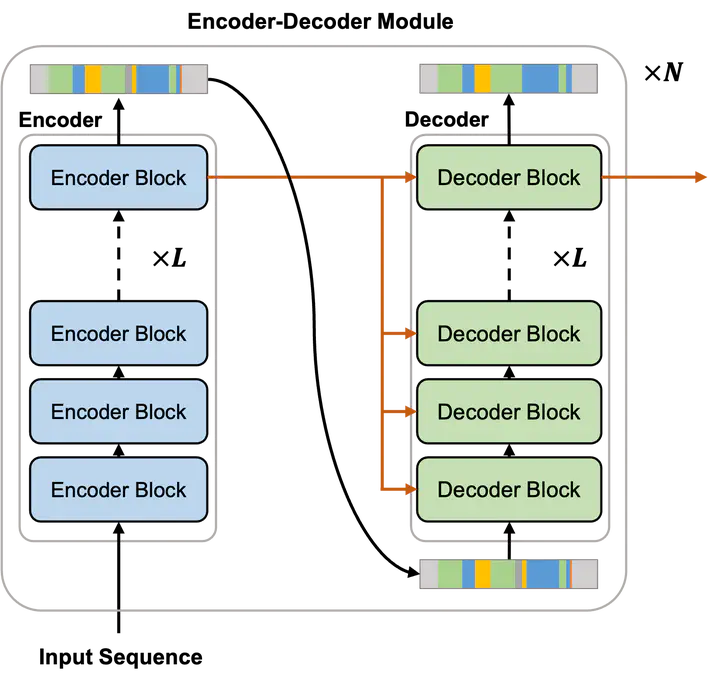
In this work, a new stacked encoder–decoder transformer (SEDT) model is proposed for action segmentation. SEDT is composed of a series of encoder–decoder modules, each of which consists of an encoder with self-attention layers and a decoder with cross-attention layers. By adding an encoder with self-attention before every decoder, it preserves local information along with global information. The proposed encoder–decoder pair also prevents the accumulation of errors that occur when features are propagated through decoders. Moreover, the approach performs boundary smoothing in order to handle ambiguous action boundaries. Experimental results for two popular benchmark datasets, “GTEA” and “50 Salads”, show that the proposed model is more effective in performance than existing temporal convolutional network based models and the attention-based model, ASFormer.