Abstract
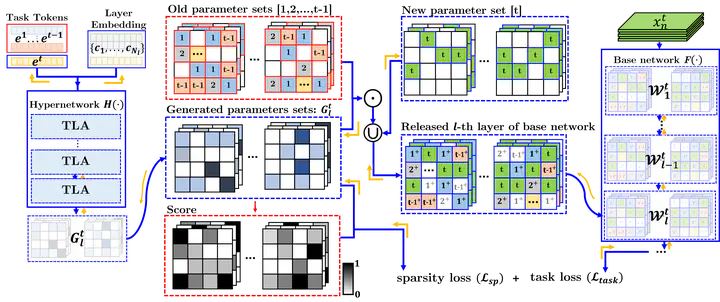
Deep neural networks suffer from catastrophic forgetting in continual learning, where they tend to lose information about previously learned tasks when optimizing a new incoming task. Recent strategies isolate the important parameters for previous tasks to retain old knowledge while learning the new task. However, using the fixed old knowledge might act as an obstacle to capturing novel representations. To overcome this limitation, we propose a framework that evolves the previously allocated parameters by absorbing the knowledge of the new task. The approach performs under two different networks. The base network learns knowledge of sequential tasks, and the sparsity-inducing hypernetwork generates parameters for each time step for evolving old knowledge. The generated parameters transform old parameters of the base network to reflect the new knowledge. We design the hypernetwork to generate sparse parameters conditional to the task-specific information and the structural information of the base network. We evaluate the proposed approach on class-incremental and taskincremental learning scenarios for image classification and video action recognition tasks. Experimental results show that the proposed method consistently outperforms a large variety of continual learning approaches for those scenarios by evolving old knowledge.